Cryptofuzz
Cryptofuzz is a project that fuzzes cryptographic libraries and compares their output in order to find implementation discrepancies. It’s quite effective and has already found a lot of bugs.

It’s been running continually on Google’s OSS-Fuzz for a while and most of the recent bugs were found by their machines.
Not all of these are security vulnerabilities, but some can be, depending on the way the API’s are used by an application, the degree to which they allow and use untrusted input, and which output they store or send.
If there had been any previous white-hat testing or fuzzing effort of the same scope and depth, these bugs would have transpired sooner, so it’s clear this project is filling a gap.
Another automated cryptography testing suite, Project Wycheproof by Google, takes a directed approach, with tailored tests mindful of cryptographic theory and historic weaknesses. Cryptofuzz is more opportunistic and generic, but more thorough in terms of raw code coverage.
Currently supported libraries are: OpenSSL, LibreSSL, BoringSSL, Crypto++, cppcrypto, some Bitcoin and Monero cryptographic code, Veracrypt cryptographic code, libgcrypt, libsodium, the Whirlpool reference implementation and small portions of Boost.
This is a modular system and the inclusion of any library is optional. Additionally, no library features are mandatory. Cryptofuzz works with whatever is available.
What it does
- Detect memory, hang and crash bugs. Many cryptographic libraries are written in C, C++ and assembly language, which makes them susceptible to memory bugs like buffer overflows and using uninitialized memory. With the aid of sanitizers, many of these bugs become apparent. Language-agnostic programming errors like large or infinite loops and assertion failures can be detected as well. For example: Memory corruption after EVP_CIPHER_CTX_copy() with AES-GCM in BoringSSL.
- Internal consistency testing. Libraries often provide multiple methods for performing a specific task. Cryptofuzz asserts that the end result is always the same irrespective of the computation method. This is a variant of differential testing. A result is not checked against another library, but asserted to be equivalent across multiple methods within the same library. For example: CHACHA20_POLY1305 different results for chunked/non-chunked updating in OpenSSL.
- Multi-library differential testing. Given multiple distinct implementations of the same cryptographic primitive, and assuming that at least one is fully compliant with the canonical specification, deviations will be detected. For example: Wrong Streebog result in LibreSSL.
What it doesn’t do
It does not detect timing or other side channels, misuse of the cryptographic API and misuse of cryptography. It will also not detect bugs involving very large inputs (eg. gigabytes). Asymmetric encryption is not yet supported.
How it works
Input splitting
The fuzzing engine (libFuzzer) provides a single data buffer to work with. This is fine for simple fuzzers, but Cryptofuzz needs to extract many variables, like operation ID, operation parameters (cleartext, key, etc), module ID’s and more.
For input splitting I often use my own C++ class that allows me extract any basic type (int, bool, float, …) or more complex types easily.
The class can be instantiated with the buffer provided by the fuzzing engine.
extern "C" int LLVMFuzzerTestOneInput(const uint8_t *data, size_t size) {
Datasource ds(data, size);
You can then easily extract anything you want:
auto a = ds.Get<uint64_t>();
auto b = ds.Get<bool>();
auto c = ds.Get<char>();
And so forth. To extract a variable number of items:
std::vector<uint8_t> v;
do {
v.push_back(ds.Get<uint8_t>());
} while ( ds.Get<bool>() == true );
Internally, the library performs length-encoded deserialization from the raw buffer into these types. As soon as it is out of data, it throws an exception, which you catch.
For more examples of this technique, see my recent fuzzers for LAME, PIEX and GFWX.
The idea multiple input data streams rather than just one, with each input type stored in its own corpus, is also prominently featured in my own fuzzer, which I hope to release as soon as I find the time for it..
Modules
The terms ‘module’ and ‘cryptographic library’ can be used interchangeably, for the most part; a module is a C++ class that is an interface for Cryptofuzz to pass data into the library code, and consume its output.
Operations
A fixed set of operations is supported. These currently include hashing (message digest), HMAC, CMAC, symmetric encryption, symmetric decryption and several KDF algorithms.
Each supported operation corresponds to a virtual function in the base class Module. A module can support an operation by overriding this function. If a module does not implement an operation, this is not a problem; Cryptofuzz is opportunistic, imposes few implementation constraints and only demands that if a result is produced, it is the correct result.
Cryptofuzz makes extensive use of std::optional. Each operation is implemented as a function that returns an optional value. This means that if a module cannot comply with a certain request, for instance when the request is “compute the SHA256 hash of the text loremipsum“, but SHA256 is not supported by the underlying library, the module can return std::nullopt.
Modifiers
A library sometimes offers multiple ways to achieve a task. Some examples:
- libgcrypt optionally allows the use of ‘secure memory’ for each operation
- OpenSSL offers encryption and decryption operation through the BIO and EVP interfaces
- BoringSSL and LibreSSL can perform authenticated encryption through both the
EVPinterface as well as the EVP_AEAD interface - Often, libraries optionally allow in-place encryption, where cleartext and subsequent ciphertext reside at the same memory location (and the other way around for decryption)
Modifiers are buffers of data, extracted from the original input to the harness, and are passed with each operation. They allow the code to diversify internal operation handling. This is important in the interest of maximizing code coverage and increasing the odds of finding corner cases that either crash or produce an incorrect result.
By leveraging input splitting, modifiers can be used for choosing different code paths at runtime.
A practical example. Recent OpenSSL and LibreSSL can compute a HMAC with the EVP interface, or with the HMAC interface, and BoringSSL only provides the HMAC interface. This is how I branch based on the modifier and the underlying library:
std::optional<component::MAC> OpenSSL::OpHMAC(operation::HMAC& op) {
Datasource ds(op.modifier.GetPtr(), op.modifier.GetSize());
bool useEVP = true;
try {
useEVP = ds.Get<bool>();
} catch ( fuzzing::datasource::Datasource::OutOfData ) {
}
if ( useEVP == true ) {
#if !defined(CRYPTOFUZZ_BORINGSSL)
return OpHMAC_EVP(op, ds);
#else
return OpHMAC_HMAC(op, ds);
#endif
} else {
#if !defined(CRYPTOFUZZ_OPENSSL_102)
return OpHMAC_HMAC(op, ds);
#else
return OpHMAC_EVP(op, ds);
#endif
}
}
Another example. A lot of the cryptographic code in OpenSSL, LibreSSL and BoringSSL is architectured around so-called contexts, which are variables (structs) holding parameters relevant to a specific operation. For example, if you want to perform encryption using the EVP interface, you’re going to have to initialize an EVP_CIPHER_CTX variable and pass it to functions like EVP_EncryptUpdate and EVP_EncryptFinal_ex.
For each type of CTX, the libraries provide copy functions. For EVP_CIPHER_CTX this is EVP_CIPHER_CTX_copy. It does what it says it does: copy over the internal parameters from one place to another, such that the copied instance is semantically identical to the source instance. But in spite of seeming trivial, this is not just an alias for memcpy; there are different handlers for different ciphers and ciphermodes and copying may require deep-copying substructures.
I created a class that abstracts creating, copying and freeing contexts. Using C++ templates and method overloading I was able to easily generate a tailored class for each type of context (EVP_MD_CTX, EVP_CIPHER_CTX, HMAC_CTX and CMAC_CTX). The class furthermore provides a GetPtr() method with which you can access a pointer to the context. (Don’t stop reading here — it will become clear 😉 ).
template <class T>
class CTX_Copier {
private:
T* ctx = nullptr;
Datasource& ds;
T* newCTX(void) const;
int copyCTX(T* dest, T* src) const;
void freeCTX(T* ctx) const;
T* copy(void) {
bool doCopyCTX = true;
try {
doCopyCTX = ds.Get<bool>();
} catch ( fuzzing::datasource::Datasource::OutOfData ) { }
if ( doCopyCTX == true ) {
T* tmpCtx = newCTX();
if ( tmpCtx != nullptr ) {
if ( copyCTX(tmpCtx, ctx) == 1 ) {
/* Copy succeeded, free the old ctx */
freeCTX(ctx);
/* Use the copied ctx */
ctx = tmpCtx;
} else {
freeCTX(tmpCtx);
}
}
}
return ctx;
}
public:
CTX_Copier(Datasource& ds) :
ds(ds) {
ctx = newCTX();
if ( ctx == nullptr ) {
abort();
}
}
T* GetPtr(void) {
return copy();
}
~CTX_Copier() {
freeCTX(ctx);
}
};
I instantiate the class with a reference to a Datasource, which is my input splitter. Each time I need to pass a pointer to the context to an OpenSSL function, I call GetPtr(). This extracts a bool from the input splitter, and decides whether or not to perform a copy operation.
Here’s my message digest code for the OpenSSL module:
std::optional<component::Digest> OpenSSL::OpDigest(operation::Digest& op) {
std::optional<component::Digest> ret = std::nullopt;
Datasource ds(op.modifier.GetPtr(), op.modifier.GetSize());
util::Multipart parts;
CF_EVP_MD_CTX ctx(ds);
const EVP_MD* md = nullptr;
/* Initialize */
{
parts = util::ToParts(ds, op.cleartext);
CF_CHECK_NE(md = toEVPMD(op.digestType), nullptr);
CF_CHECK_EQ(EVP_DigestInit_ex(ctx.GetPtr(), md, nullptr), 1);
}
/* Process */
for (const auto& part : parts) {
CF_CHECK_EQ(EVP_DigestUpdate(ctx.GetPtr(), part.first, part.second), 1);
}
/* Finalize */
{
unsigned int len = -1;
unsigned char md[EVP_MAX_MD_SIZE];
CF_CHECK_EQ(EVP_DigestFinal_ex(ctx.GetPtr(), md, &len), 1);
ret = component::Digest(md, len);
}
end:
return ret;
}
I instantiate CF_EVP_MD_CTX as ctx once, passing a reference to ds, near the top of the function.
Then, each time I need access to the ctx, I call ctx.GetPtr(): once as a parameter to EVP_DigestInitEx(), once to EVP_DigestUpdate() and once to EVP_DigestFinal_ex().
Each time ctx.GetPtr() is called, the actual context variable EVP_MD_CTX may or may not be copied. Whether it is copied or not depends on the modifier. The contents of the modifier is ultimately determined by the mutations performed by the fuzzing engine.
This approach is more versatile than copying the context only once, because this will catch bugs that depend on context copying at a specific place, or as part of a specific sequence, whereas copying it just once potentially comprises a narrower state space.
Input partitioning
It is common for cryptographic libraries to allow the input to be passed in steps. If you want to compute a message digest of the text “loremipsum”, there are a large amount of distinct hashing steps you could perform. For example:
- Pass lorem, then ipsum
- Pass lor, then em, then ipsum
- Pass lor, then em, then ip, then sum.
And so forth. To test whether an input always produces the same output regardless of how it’s partitioned, all current Cryptofuzz modules will attempt to pass input in chunks where it is supported.
Helper functions are provided to pseudo-randomly partition an input based on the modifier, and implementing is often as easy as:
Datasource ds(op.modifier.GetPtr(), op.modifier.GetSize());
util::Multipart parts = util::ToParts(ds, op.cleartext);
for (const auto& part : parts) {
CF_CHECK_EQ(HashUpdate(ctx, part.first, part.second), true);
}
Operation sequences
The same operation can be executed multiple times. This is even necessary for differential testing; to discover differences between libraries, the same operation must be executed by each library before their results can be compared.
Each time the same operation is run, a new modifier for it is generated.
So we end up with a sequence of identical operations but each run by a certain module, and each with a new modifier.
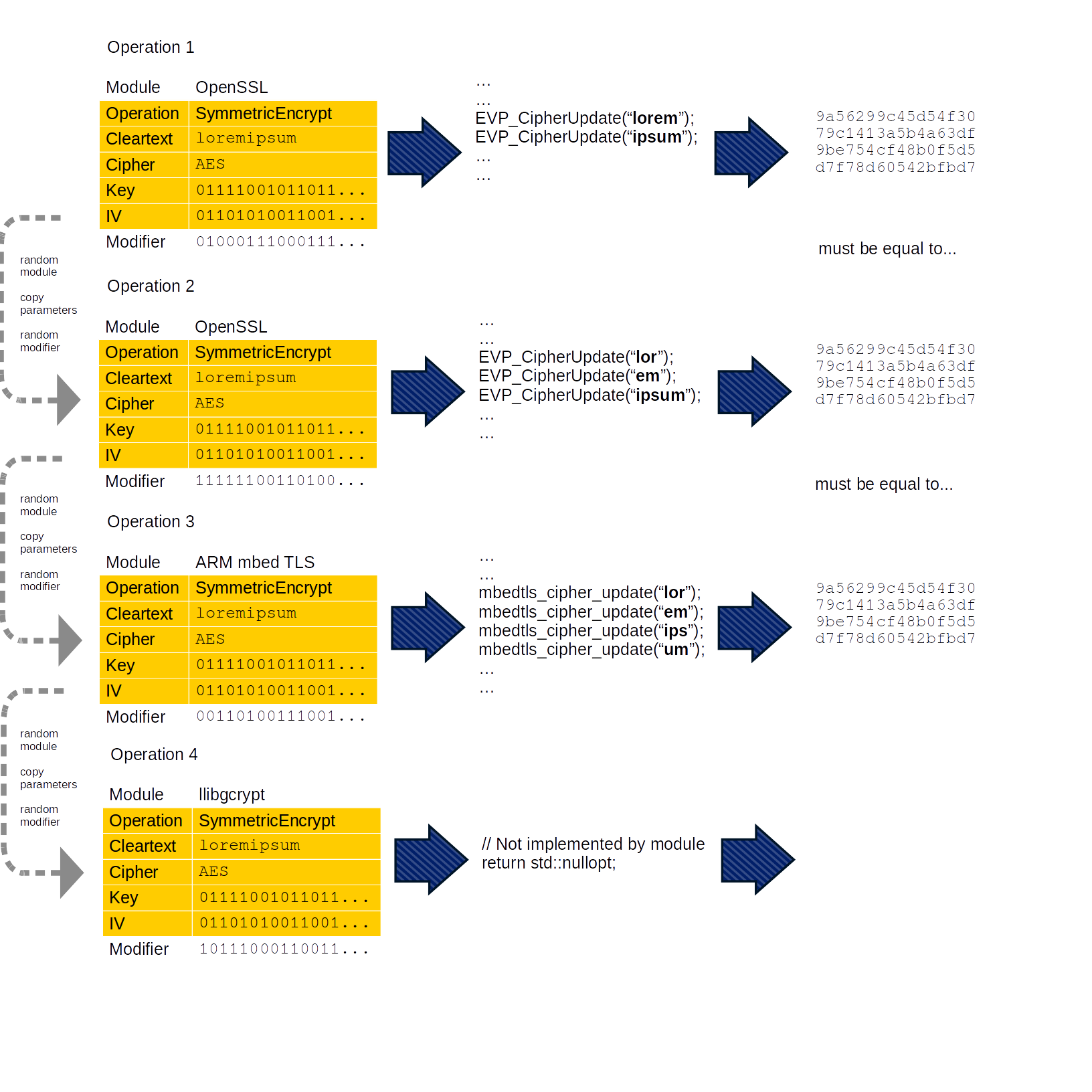
Once the batch of operations has been run, Cryptofuzz filters out all empty results. In the remaining set, each result must be identical. If it is not, then Cryptofuzz prints the operation parameters (cleartext, cipher, key, IV, and so on) and the result for each module, and calls abort().
Multi-module support
Modules, along with the cryptographic library that they implement, are linked statically into the fuzzer binary.
More libraries do not necessarily make it slower. Each run, Cryptofuzz picks a set of random libraries to run an operation on. Adding more libraries does not cause an increase in total operations; only a few operations will be executed each run, regardless of the total amount of modules available.
Additional tests
Each time an encryption operation succeeds, Cryptofuzz will attempt to decrypt the result using the same module. If the decryption operation either fails, or the decryption output is not equivalent to the original cleartext, a crash will be enforced.
Cryptofuzz also allows “static” tests that operate on a single result. Here is a postprocessing hook that gets called after a SymmetricEncrypt operation, and detects IV sizes larger than 12 bytes in encrypt operations with ChaCha20-Poly1305, which is a violation of the specification (see also OpenSSL CVE-2019-1543 which was not found by me but upon which I based this test).
static void test_ChaCha20_Poly1305_IV(const operation::SymmetricEncrypt& op, const std::optional<component::Ciphertext>& result) {
using fuzzing::datasource::ID;
/*
* OpenSSL CVE-2019-1543
* https://www.openssl.org/news/secadv/20190306.txt
*/
if ( op.cipher.cipherType.Get() != ID("Cryptofuzz/Cipher/CHACHA20_POLY1305") ) {
return;
}
if ( result == std::nullopt ) {
return;
}
if ( op.cipher.iv.GetSize() > 12 ) {
abort();
}
}
void test(const operation::SymmetricEncrypt& op, const std::optional<component::Ciphertext>& result) {
test_ChaCha20_Poly1305_IV(op, result);
}
Funding
I’ve been working on this project full-time for several months. I suppose I could seize this opportunity to say that I do this to save the planet from the apocalypse due to a signed integer overflow in OpenSSL, but I’m really just addicted to staring at fuzzer statistics ;).
It’s a lot of fun, but also a lot of work.
I’m especially interested in exploring the fringes of an API’s legal use, and this requires a close reading of the documentation, getting my implementation exactly right and if I get a crash or odd result, working out whether this is due to a fault of my own or not.
Perhaps surprisingly, writing good bug reports is a lot of work. Ideally I want to present readily compilable proof of concept code to the library maintainers so that they won’t have to get bogged down in my fuzzer’s technical details in order to understand a bug in their own code.
I’m proud of the project as it stands, and I’d love to expand it to support more very widely used libraries like Go and Java’s cryptographic code. Considering what I’ve seen so far, I’d be surprised to not find more bugs in popular cryptographic software.
Google has rewarded me $1000 for initial integration of Cryptofuzz into OSS-Fuzz, for which I’m grateful. This is all the income this project has generated so far, and I’m not complaining because it was a hobby project from the outset, but going forward I will have to forgo Cryptofuzz enhancements in pursuit of more profitable ventures, for the simple reason that I need an income and can’t spend all my time on hobby projects forever.
I submitted a grant proposal to the Core Infrastructure Initiative about one month ago. This project seems to align largely with their objectives. Unfortunately, I have not yet received a response.
If you rely on some cryptographic library (Go? Java? Rust? Javascript?) and would like to fund its integration into Cryptofuzz, please get in touch.
Edit 26 September 2019: In addition to the $1000 initial integration reward, I’ve received an additional $5000 from Google for ideal integration. A private person has also donated two $100 Amazon gift cards, which I’ve partially spent on purchasing a Raspberry Pi 4 for testing cryptographic libraries on ARM. The Core Infrastructure Initiative never responded.
Edit 24 October 2019: 35 bugs found. Someone donated $1,000 (thanks again) and I’ve submitted a grant proposal to RIPE NCC’s Community Projects Fund. I’ve been working on elliptic curve cryptography support in a separate branch and will merge this soon.

For elliptic curve cryptography, I have already done https://github.com/catenacyber/elliptic-curve-differential-fuzzer which is integrated in oss-fuzz and found one bug in cryptopp… and was inspired by this work in the first place if I remember correctly.
How do you manage to differentiate the crashes ?
Hello Philippe,
I’m aware of your elliptic curve differential fuzzer. Perhaps you were inspired rather by my bignum fuzzer? https://github.com/guidovranken/bignum-fuzzer . It has been around a bit longer.
Which bug in Crypto++ did you find? Since this blog post I’ve integrated EC fuzzing support in CryptoFuzz as well, and I wonder if it could find the bug you found.
I differentiate between crashes by creating an ASSERT message with the module names, operation name, and cipher/hash name.
Eg: https://bugs.chromium.org/p/oss-fuzz/issues/detail?id=15807&q=cryptofuzz&can=1
This works well with OSS-Fuzz.